

The processor in your home’s wireless router could boost the speed of tomorrow’s high-performance computing (HPC) systems. These computer chips, called field-programmable gate arrays (FPGAs), can be programmed – traditionally with a hardware description language (HDL) – and run fast on a smidgen of power.
Hal Finkel – lead for compiler technology and programming languages at the Department of Energy’s Argonne Leadership Computing Facility, a DOE national user facility – has been exploring using FPGAs for scientific HPC in collaboration with Kazutomo Yoshii and Franck Cappello from Argonne’s Mathematics and Computer Science Division.
Eventually, physics will forbid engineers from putting more standard processor cores (central processing units, or CPUs) or graphics processing units (GPUs) on a chip. “When we stop being able to make things smaller, stop being able to put more cores on a chip, how do we keep making progress?” Finkel asks. In their quest for faster and more efficient computer architectures, researchers may turn to FPGAs, which, Finkel says, “can be used more than an order of magnitude more efficiently than a traditional CPU or GPU.”
FPGAs cut energy use by moving data less than traditional processors. Moving data on a chip affects an HPC system’s energy budget more than a typical user might imagine. “An interesting thing about really modern computer architecture,” Finkel notes, “is that the cost of moving data on a chip can be more than the energy needed to do the computation.”
Picture a chip as a grid in which each square represents some process that can be applied to data. For a CPU or GPU, the data goes to a square to complete the process, then back to the beginning – to the register file – and then to a different square, back to the beginning after that, and so on. With an FPGA, it’s more like hopscotch, with the computation starting at the beginning, then hopping to one square and then another. “You move across the grid, going directly from one thing you want to do to another, and that’s more efficient,” Finkel explains. The data move from square to square with the program, instead of the CPU/GPU way of beginning, square, beginning, another square, beginning. “You’re not doing as much data movement with an FPGA, and that provides a big efficiency gain.”
FPGAs might already be ubiquitous in HPC if programmers didn’t find them so difficult to use. “First, you had to program in an HDL,” Finkel says. Next, compiling a program – translating programming into instructions a computer can read – can take hours. On top of that, FPGAs work well with whole-number math but so well with floating point calculations involving decimals. Scientific computing often needs floating-point math, and vendors are just starting to add it to FPGAs. Finkel and team hope to take advantage of that.
The team wants to put scientific applications on FPGAs and build a programming environment that can be used by the existing workforce, including C++ and Fortran programmers and those who use OpenMP for parallel applications. “How can we enable that to work on FPGAs and get the benefits that they bring?” Finkel asks.
Some FPGA features simplify making them into scientific HPC processors, and one of those is parallelism, which divides problems into pieces that are sent to multiple cores for simultaneous solution. “FPGAs are very good at parallelism,” Finkel says. “In fact, they essentially have to be used that way” because getting the most out of the grid of processes means using the boxes simultaneously. “To use all of these boxes, you need to start a bunch of stuff at the same time.” That way, the entire FPGA is used as data move through it.
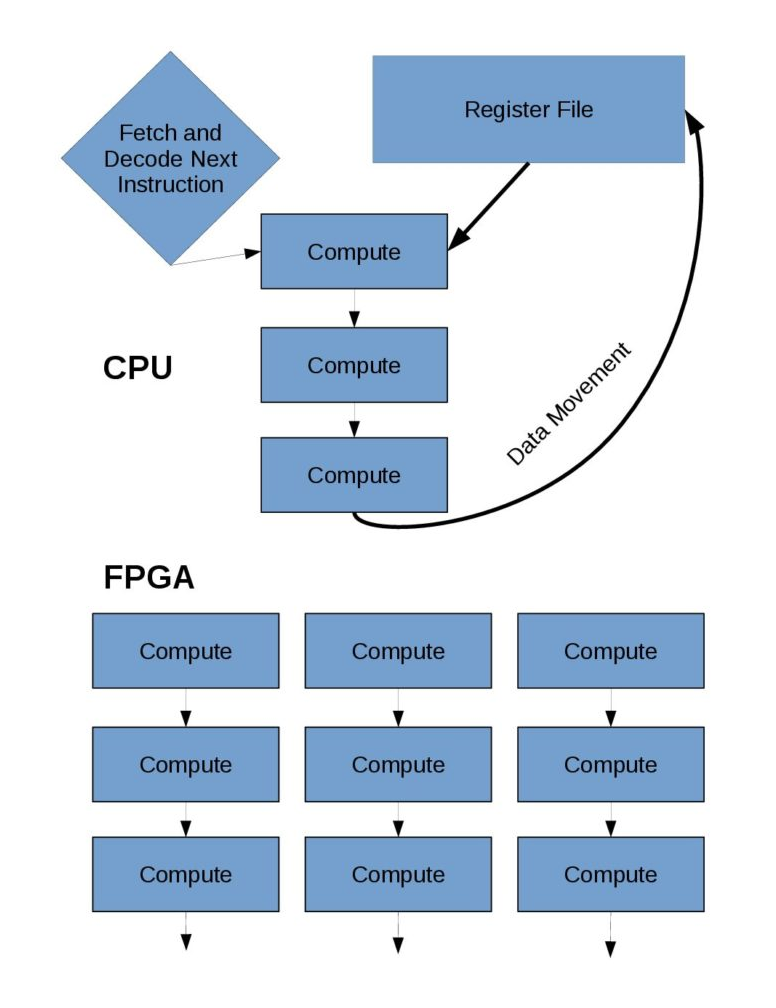
To keep those parallel processes under control, programmers must create a pipeline that starts new computations on every cycle. That keeps a variety of computations working through an FPGA all the time, with different calculations possibly proceeding in different parts of the chip.
With just HDL for programming, it takes more than inherent parallelism to make FPGAs more likely to appear in tomorrow’s HPC architectures. Manufacturers use HDL to program physical hardware and chips, but it’s not what most software developers use. FPGA programming is getting easier, Finkel says, yet “it’s still not as easy as a GPU or CPU.”
FPGA manufacturers have helped make them easier to use by adding an open computer language (OpenCL) environment, which was originally created to program GPUs. As compared to HDL, OpenCL seems more familiar to most programmers, like a version of C with added capabilities. In the future, the technology supporting OpenCL also will enable the use of C++ and Fortran with OpenMP on FPGAs.
Compile time remains an issue, but Finkel hopes to alleviate some of that. “We are working on a set of techniques called overlay architecture to help improve the compile time,” he says, “but that work is fairly preliminary.”
To test some of these theories, the team put benchmarks representing scientific applications on FPGAs to see if performance increases and energy use drops. “It appears to be true,” Finkel says.
In this work, Finkel and the team showed that, compared to a CPU, an FPGA can use one-quarter of the power and achieve a higher percentage of its available peak throughput. “If you had a CPU and an FPGA with similar peak bandwidth,” Finkel explains, “the FPGA will perform better.”
Getting to faster HPC depends on more than computation, however. “Lots of applications tend to be bottlenecked on accessing data from memory,” Finkel says. FPGAs might alleviate that, too. With CPUs, lots of energy goes to updating and maintaining a data cache, but a cache is unnecessary in an FPGA if the programmer doesn’t want one. Instead, they can program an FPGA to issue smaller requests to memory when need smaller pieces of data are needed. FPGAs also can enable on-the-fly data compression or decompression, which can increase the system’s effective memory bandwidth.
An FPGA apparently produces higher performance at a lower cost than a CPU or GPU. If Finkel and his collaborators can make these chips more user friendly, tomorrow’s HPC could leave today’s in the dust.