
The cost of failure can be steep, nowhere more so than in high-performance computing. Broken node electronics, software bugs, insufficient hardware resources, communication faults – they are the bane of the computational scientist. They also are inevitable.
Addressing fault tolerance and efficient use of distributed computing has become urgent as the number of computing nodes in the largest systems has increased. Using a technique called selective recovery, Sriram Krishnamoorthy of Pacific Northwest National Laboratory and his computational science colleagues have demonstrated that petascale computing – and eventually exascale – will depend on a dramatic shift in fault tolerance.
“The basic idea of dynamic load balancing is you can react to things like faults online,” Krishnamoorthy says. “When a fault happens, we showed you could actually find what went bad due to the fault, recover that portion and only that portion and then re-execute it” while everything else continues to execute.
Typically, when high-performance computing systems fail, the process rolls back to the last checkpoint, a record of the calculation’s state, then re-executes the failed task across all nodes. That method works well, but consumes a lot of time and space on the system.
“When one process goes bad and you take a million of them back to the last good checkpoint, it’s costly,” he says. “We showed that the cost of a failure is not proportional to the scale at which it runs.”
With the new method, described last year at the International Supercomputing meeting, when there is a failure, only the faulty process is rerun, while the computer continues without interruption. The method relies on a system of checks that ignores duplications and synchronizes results in a given task. It also keeps tabs on the overall job through data structures that are globally accessible, rather than stored in local memory, thereby reducing communication.
Krishnamoorthy began his work improving the efficiency of algorithms as a graduate student at Ohio State University. When he joined PNNL in 2008, he found a collaborator in Karol Kowalski, a computational chemist working to model the behavior of organic molecules that can shift their electronic state to harvest energy from light. Later the molecules can release that energy to generate electricity. Currently, solar panels use inorganic arrays to perform the same function, but organic photovoltaics may be more flexible if they can be made efficiently. To guide a would-be builder to an organic molecular system that efficiently transforms solar energy into electricity, Kowalski models the behavior of electrons within these molecules at various excited states. But the computational power required to model even a simple system with a few electrons quickly becomes prohibitive when using standard methods.
“The problem is not just the increasing numbers of atoms but also the numerical cost of these calculations,” Krishnamoorthy says. “As you double the number of electrons, you have more than a hundred times more work to do. The question becomes how do you run these calculations as efficiently as possible, so that given a particular machine and time, what is the largest (molecular) system you can run?”
Krishnamoorthy quickly went to work to determine how to adapt Kowalski’s models for efficiency and to run the algorithms on much larger parallel systems.
“Karol wanted to work on excited states and equation-of-motion coupled-cluster methods,” Krishnamoorthy says. “These are electronic structure calculations that we are solving with varying degrees of approximation. First, you solve the time-independent solution to the electronic structure for a base structure in the ground state. Then with equations of motion you are studying a variety of excited states. My role was essentially to see what it takes to solve such a problem on the latest machine of interest.”
Krishnamoorthy and his team worked on porting or optimizing the codes to run on Jaguar, Oak Ridge National Laboratory’s Cray XT5 system. Now the PNNL scientists are doing something similar on Jaguar’s successor, Titan.
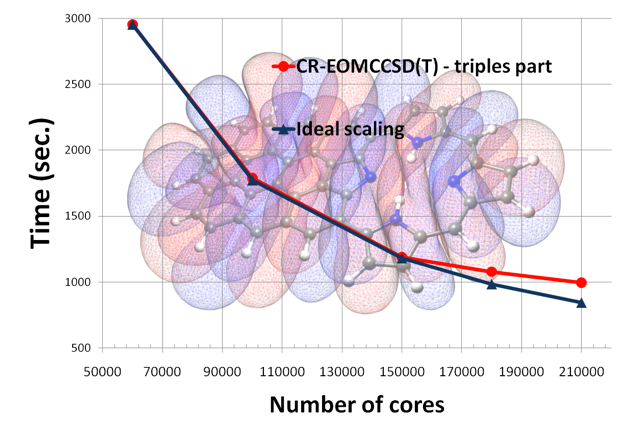
Recently, the research team demonstrated that the most computationally intensive portion of the calculation can be run on 210,000 processor cores of Titan, a Cray XK7 at Oak Ridge’s Leadership Computing Facility, achieving more than 80 percent parallel efficiency.
“When I joined PNNL we were still looking at codes that run on a few thousand cores,” Krishnamoorthy says. When Chinook, the lab’s computational chemistry machine, arrived, “we were immediately jumping up to 18,000 cores.” Doing one calculation at a time and constantly shuttling data to disk drives “was not going to suffice.”
Tackling and solving the jump to highly parallel computing and innovating how the system deals with workload and faults earned Krishnamoorthy a DOE Early Career Research Program award. It grants him $2.5 million over five years to explore ways he can extend his ideas to exascale computing. Shortly thereafter, Krishnamoorthy learned he had also been awarded PNNL’s 2013 Ronald L. Brodzinski Award for Early Career Exceptional Achievement.
He’s now broadening the methods developed for computational chemistry to apply to any algorithm that has load-imbalance issues.
“You want a dynamic environment where the execution keeps on going and the user doesn’t have to worry about statically scheduling everything – the run-time engine just automatically adapts to changes in the machine and in the problem itself,” he says.
The current framework is called Task Scheduling Library (TASCEL) for Load Balancing and Fault Tolerance.
“We are now trying to adapt this method to the new codes as they are developed,” Krishnamoorthy says. He wants moving one version of a program to the next generation to be seamless, by automating the process.
“You have to write the program in terms of collections of independent work or tasks and the relationships among them in terms of who depends on who and what data they access,” he says. “As long as it is written this way, the run-time can take over and do this load balancing, communication management and fault management automatically for you.”
His methods address two of the most daunting challenges facing exascale computing: load imbalance and fault tolerance. He’s contemplating not what computers will look like in the next two to three years but instead what challenges there’ll be with applications running on exascale computers eight to 10 years from now.
The cost of failure can be steep, but Krishnamoorthy is making it less so every day.